|
Für die Suche nach einer bestimmten Zeichenkette am Anfang einer Zeile in einer (Text-) Datei steht ein einfaches und schnelles Dienstprogramm in einigen Linux-Distributionen bereit. Ohne Angabe einer Datei wird das Standardwörterbuch ("/usr/share/dict/words") durchsucht. Das Programm ist insbesondere bei der Suche in Wörterbüchern sehr hilfreich und eignet sich nicht für komplexere Suchanfragen. Da das Dienstprogramm eine Binärsuche durchführt, müssen die Zeilen in der Datei sortiert sein.
So geht's:
- Starten Sie die entsprechende Linux-Distribution (z. B. "" oder "").
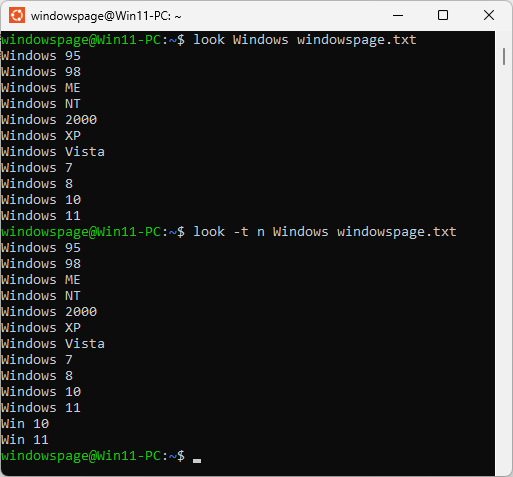
- Als Befehl geben Sie "" ein. Z. B.: ""
- Drücken Sie die Eingabetaste.
- Es werden alle Zeilen, die mit "Windows" beginnen, ausgegeben.
Tabelle der Befehlsparameter (Auszug):
| Parameter: |
Kurzbeschreibung: |
| -a |
Verwendet die alternative Wörterbuchdatei ("/usr/share/dict/web2"). |
| -d |
Es wird der normalen Zeichensatz und die Reihenfolge des Wörterbuchs verwendet. Dies ist standardmäßig aktiviert, wenn keine Datei angegeben wird. |
| -f |
Die Groß-/Kleinschreibung von Buchstaben wird ignoriert. Dies ist standardmäßig aktiviert, wenn keine Datei angegeben wird. |
| -t |
Gibt ein Zeichen zur Markierung des Zeichenkettenendes an. Es werden nur Zeichen bis einschließlich des ersten Vorkommens verglichen. |
Beispiele:
- Das Standardwörterbuch "/usr/share/dict/words" verwenden und alle Zeilen, die mit "linux" beginnen, ausgeben:
""
- Alle Zeilen der Textdatei "windowspage.txt", die bis zum Trennzeichen "n" und mit "Windows" beginnen, ausgeben :
""
- Die Groß- und Kleinschreibung ignorieren und alle Zeilen der Textdatei "windowspage.txt", die mit "windows" beginnen, ausgeben:
""
Hinweise:
- Weitere Optionen zur Steuerung können mit dem Befehl "" ausgegeben werden.
- Der Befehl "" ist nicht in allen Linux-Distributionen enthalten.
Querverweise:
|